有必要在本地部署AI大模型吗?
一段时间以来,我一直在用ChatGPT、DeepSeek、Poe这些AI人工智能辅助内容创作,这玩意儿虽好,但作为一个人类来说,真不能太依赖AI了,不然时间久了脑子就秀逗了,没有思考能力了。
最近刷了很多关于本地部署AI大模型的视频,总感觉这些人是在折腾,首先得购买配置高的电脑,然后又鼓捣各种代码,看的头大,直接在线用DeepSeek这些AI不好么?既然有这个市场,存在即合理。最近买了一款AI硬件产品,有一个小屏幕,仅可以语音对话,平时跟她聊聊天,台湾腔的女声口音让人听着很上头,有更改声音,更改大模型这些功能。在登陆到其官网设置后台时,发现与这个AI硬件的聊天记录都以文字的形式保存在了服务器中,固然可以进行删除操作,但毕竟隐私的对话都处于泄露状态,AI硬件厂商完全有权限浏览用户聊天对话内容。同理,用户在线使用那些热门AI时,所会话内容及上传的文件,也都能被AI厂家获取,所以,在本地离线不联网状态使用AI大模型交互一些敏感机密内容是有必要的,尤其对政企用户。
没有高配置电脑,不懂代码,可以傻瓜式在本地部署大模型吗?
当然可以。“GPT4All”就是一个让普通用户可以简单快速在本地部署大模型的工具软件。它有如下特点:
- 免费,其实是个人用户免费,企业用户收费这样,付费订阅需使用万事达Visa虚拟信用卡
- 开源
- 无需高性能硬件,一般配置的GPU、CPU电脑一样可以正常运行
- 无需联网,完全不依赖网络即可使用
- 可在本地访问用户机密敏感文件,无需上传至互联网,保护用户数据安全
- 内置市面上各种主流大模型,用户可自主切换使用
关于上述第3条,至于为什么GPT4All无需高端显卡就能运行大模型,我通过询问DeepSeek得到的答案是:“GPT4ALL不需要高端GPU主要是因为其模型经过优化,能够在CPU上高效运行,且模型规模较小、计算需求较低,适合在本地设备上运行。此外,作为开源项目,GPT4ALL 具有高度可定制性,能够适应不同硬件环境,使其无需依赖GPU即可在普通设备上流畅运行。”
开始操作,用GPT4All在本地部署大模型LLM
GPT4All的使用方法非常简单,首先登陆其官网:https://www.nomic.ai/gpt4all,下载跟你电脑操作系统匹配的安装包,例如Windows。然后安装。
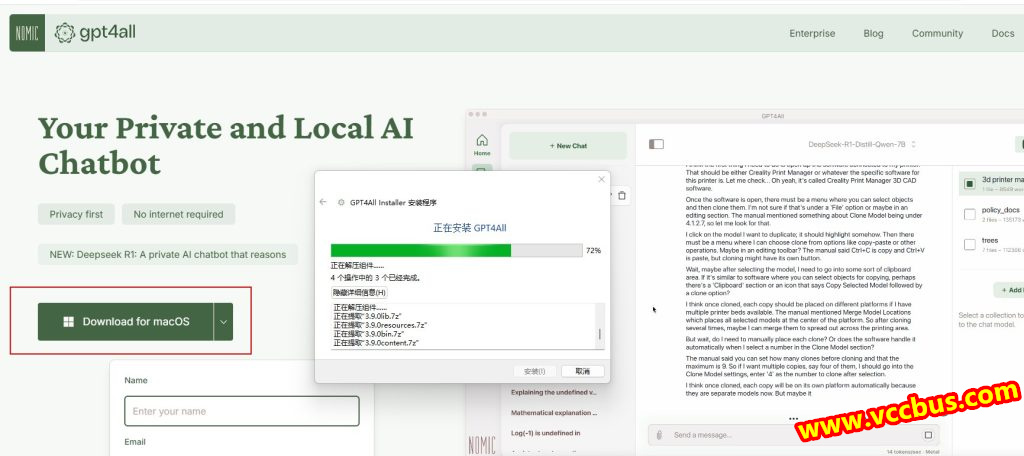
安装后进入“模型”页面,选择你需要的大模型,当前比较热门的DeepSeek R1、Qwen2.5、Llama等这些都有的。这里标注有该大模型所占硬盘、内存空间、参数等信息,若是本地电脑配置比较低,则会有红色提示不推荐下载安装。
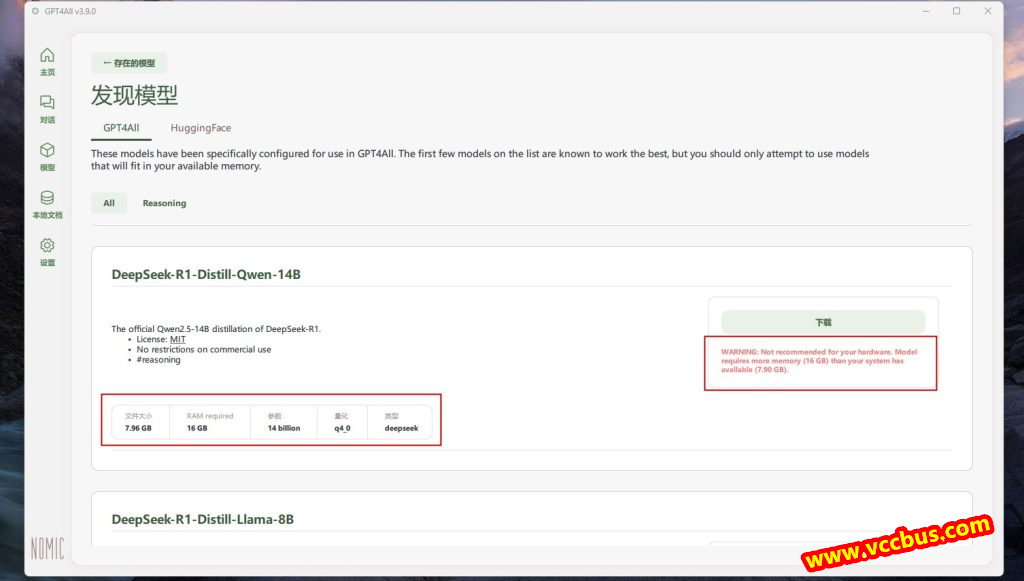
有的大模型例如ChatGPT-4不是下载安装这种用法的,而是要输入OpenAI API密钥远程调用。
这里下载并安装了Meta AI公司的Llama 3.2大模型。
最后进入“对话”页面,上方选择已安装的大模型,正常人机对话即可。
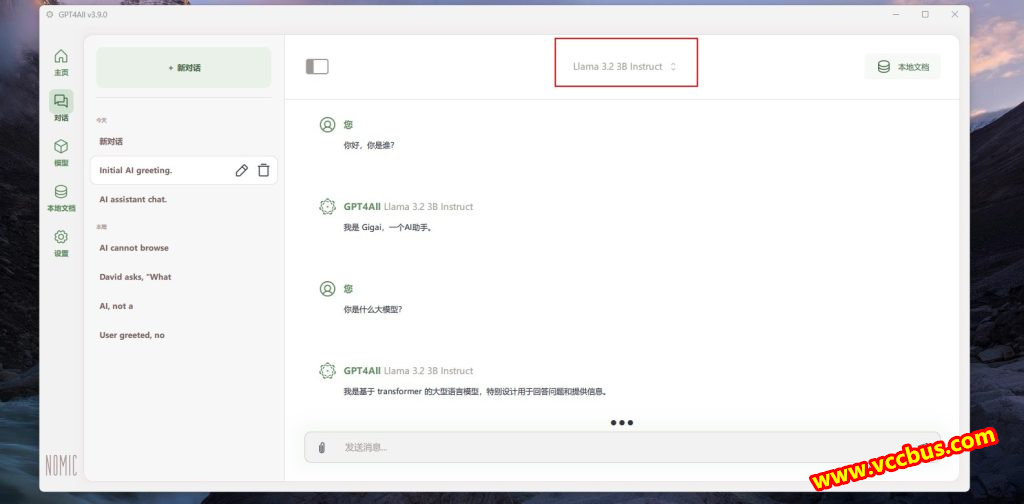
就这么简单,就完成了大模型在本地电脑部署。由于我的电脑的性能比较低,导致Llama响应速度也比较慢,换成Qwen大模型响应速度会快一些。
如何让GPT4ALL读取调用本地文件?及简单测试
在本地电脑部署大语言模型最主要用途就是让其读取我们本地文件来进行输出,对于企业用户来说,可能是比较机密财务报表、人事档案、会议纪要等文件。
首先要做的就是创建一个本地文档文件夹,进入左侧菜单“本地文档”,填写一个名称,选择一个文件夹目录,这样就可以了,然后把需要让AI读取的文件放到这个文件夹内。
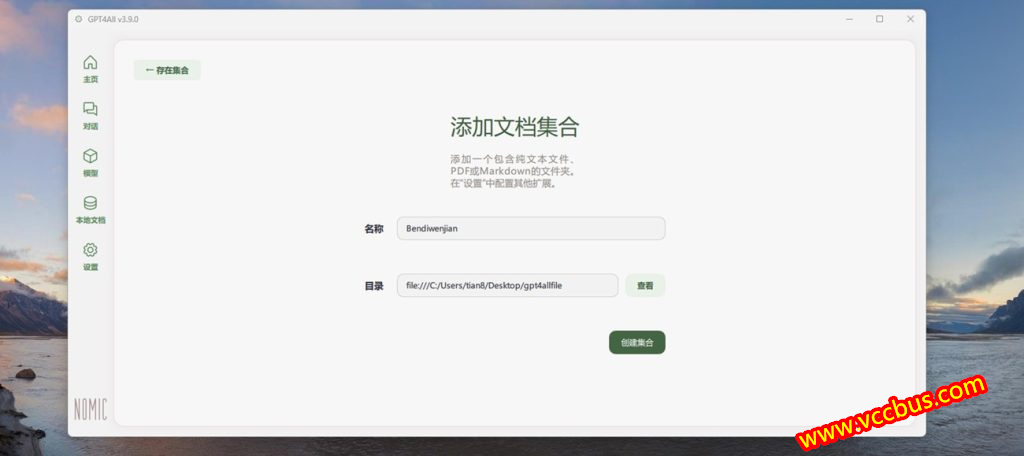
创建好本地文件夹并导入文件后,在会话框页面右上角就会看到一个可勾选的“本地文档”按钮,需要让大模型读取本地文件的话,就勾选这个。
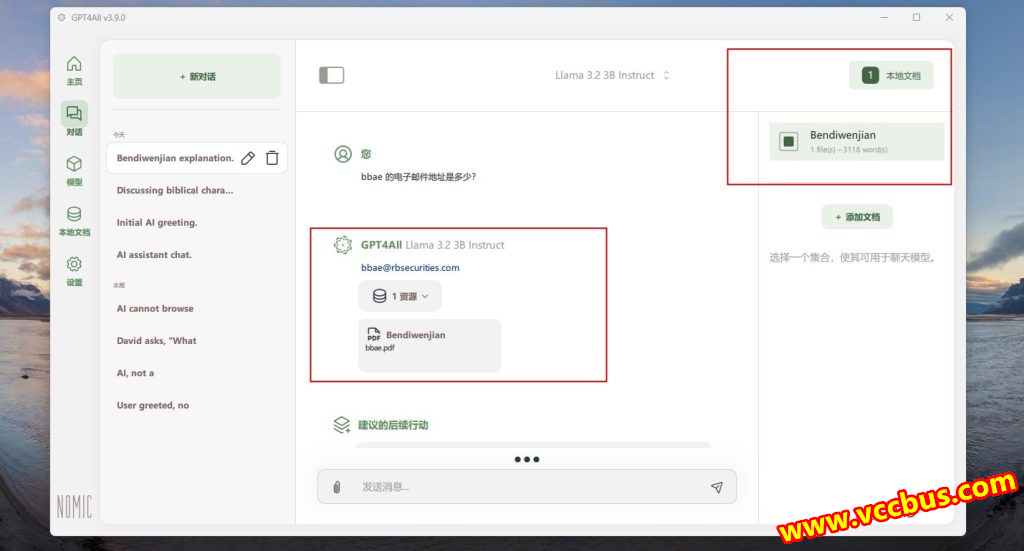
那么来做个简单测试,看大模型能否成功调用读取本地文件。首先把一份BBAE必贝证券的PDF电子账单投喂到了本地文件夹内,然后询问大模型“bbae的电子邮件地址是多少?”,它给出了正确的反馈信息,输出了这个电子邮件地址,下方显示AI成功读取了本地文件资源。
而如果不勾选本地文件,询问同样的问题,大模型的回答便是“我无法提供个人或特定用户的电子邮件地址”了。
关于GPT4ALL读取本地文件工作原理,官方的表述是:LocalDocs本地文档这个工具会用Nomic AI提供的一个免费又快速的模型,把用户文件夹里的文件变成一段段文字,并且给每一段文字生成一个特殊的“向量”(可以理解成一段文字的数学表示)。这些向量能帮用户找到聊天时输入的问题或提示意思相近的文字片段。然后,GPT4ALL会把这些相关的文字片段放到给大语言模型(LLM)的提示里,让它更好地理解用户的问题并给出回答。
需要注意的是,导入本地文件夹内的文档最好是可读的txt、xlsx、docx、文本形式的PDF文档,那种里边是图片形式的PDF文件中的文字内容无法识别。
相关阅读: